
Interesting Intersections
I wrote some code to automatically map stylized pictures of horrible road intersections from your favorite city. Demo here.
I recently stumbled on a beautifully designed poster that called attention to the ridiculousness of Seattle street intersections and road layout:
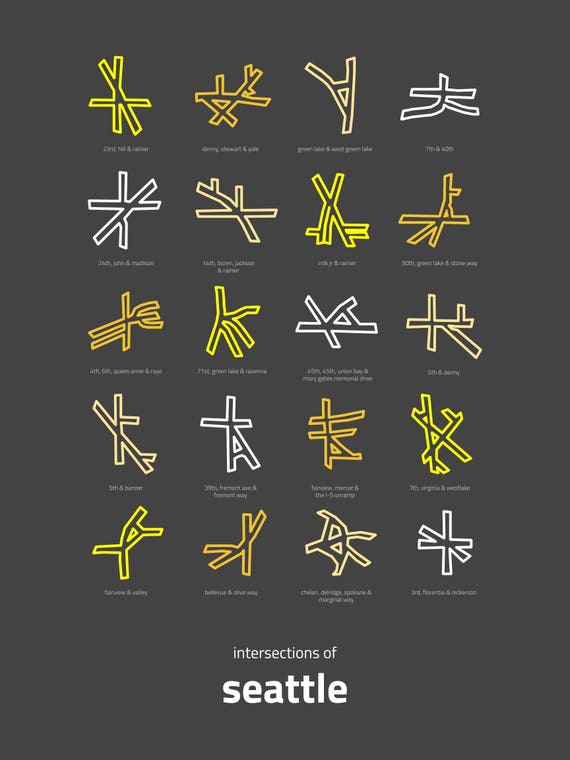
I immediately thought of Baltimore’s equally — perhaps even more — absurd roads. The people in charge of designing Baltimore’s road system should be punished by having to drive here.
I can think of a few crazy intersections — and some other great traffic patterns, like the Washington Monument which is three quarters of a traffic circle and then one quarter is paradoxically reversed so you’re driving into oncoming traffic…
Or this spectacular disaster:
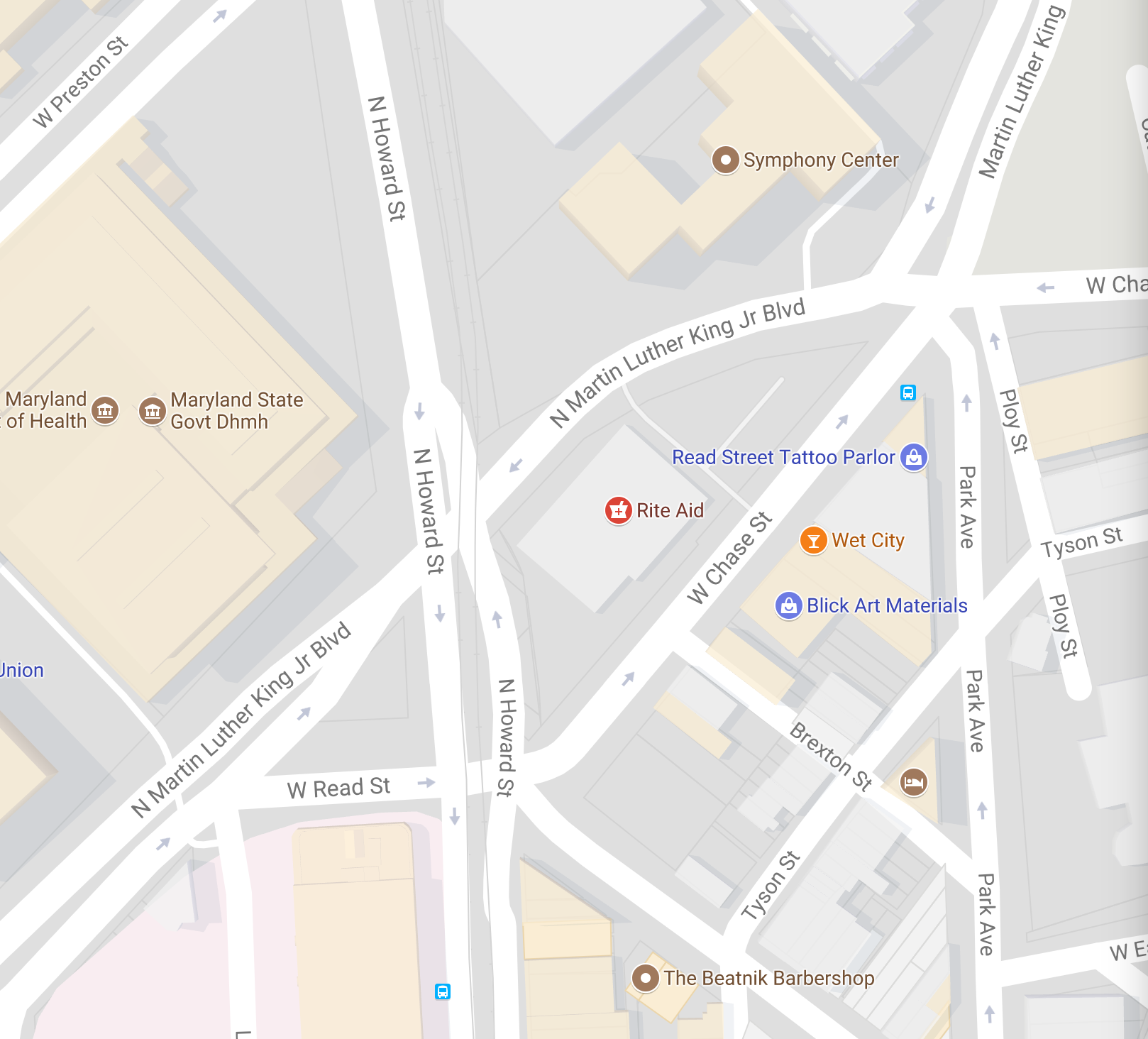
Frankly, there are too many of these catastrophic mistakes to enumerate by hand. But a computer could do it, right?
OpenStreetMap is a free and open data-repository for mapping the planet, like a less-ad-laden Google Maps, queriable by API call.
To begin, I found Python libraries overpy and osmnx to interface with the Overpass and OpenStreetMap APIs (respectively).
The Tricky Part
The tricky part: How do you quantify suckiness of an intersection? And how do you even find intersections to begin with?
If you look at a graph of a city’s streets, where intersections are nodes with greater than two incident edges, it’s unclear where bad intersectons are (versus just regular intersections). And a crossing of two large roads each separated by a median would have four high-degree nodes, even though it’s a very straightforward intersection.
My (mediocre) solution was to use traffic-lights as a proxy for complexity. The more different traffic lights at an intersection, the more complex. (OSM encodes only one traffic light per “direction”, so if you have four actual lights but they all turn green at the same time, it just counts as one.)
So the challenge is to find high densities of “disagreeing” traffic lights per square-foot of roadspace.
To do this, I wrote the following GeoQL query:
[out:json]
[timeout:2500]
;
area["name"="[[CITY]]"]->.searchArea;
(
node
["highway"="traffic_signals"]
(area.searchArea);
way
["highway"="traffic_signals"]
(area.searchArea);
relation
["highway"="traffic_signals"]
(area.searchArea);
);
out;
>;
out skel qt;
This can be transformed into a list of $(x, y)$ pairs by passing this query through overpy and mapping the result nodes as a numpy array.
To reduce the noise a bit, I then used a distance matrix to filter out traffic lights that were either alone or far from neighbors. Here’s that resultant 2D matrix:
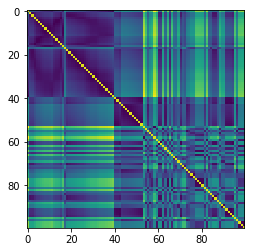
Read it like “the traffic light at index 23 and the light at index 47 are matrix[23, 47] apart” (where the distance is in an arbitrary unit).
Once these loners have been removed — and it really is worth doing this, because we can expect the clustering algorithm to move much faster without them — I use DBScan from scikit-learn to identify clusters.
Formatting
After the traffic lights are clustered, I take the centroid of each cluster and use osmx to query OpenStreetMap again, but this time for a network of roads, centered on that cluster. I then use networkx to render stylized images of the graphs (nodes of zero radius, edges with high thickness) with a transparent background; these can then be used on the web, as in my demo.
As a bonus, I geocode by city-name based on arguments to the command-line tool; so you can check your own city without having to modify too many queries. (The Overpass query language is, it turns out, pretty frustrating to learn.)
Results
Most of the results that the system generates are pretty good: They’re complex intersections (the sort that make you go “ew” when you see them), but they’re not too complex as to not fit on screen.
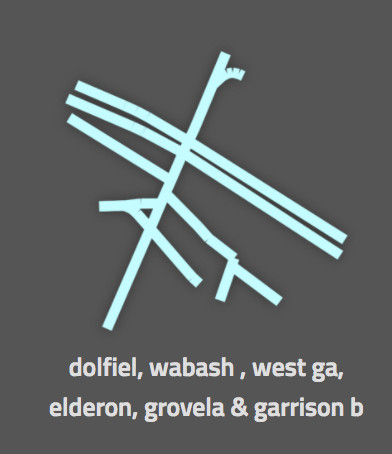

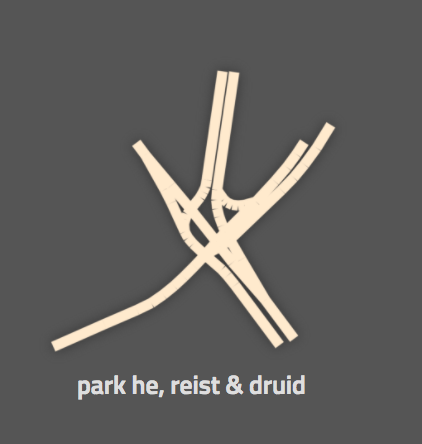
Other results are less exciting: Here’s an example of a case where, despite a large number of traffic signals, this intersection is actually probably pretty manageable, because it’s all on- and off-ramps:
In general, I’m happy with the results; but if you’re not, you can check out the code on GitHub and make the changes you want to see in the world.