
Serving my serverless personal website
I recently migrated my personal website over from a “serverful” virtual machine to exclusively use AWS’s serverless offerings. I’ve previously worked pretty extensively with serverless systems — bossDB is a serverless volumetric database I use nearly every day at work, and FitMango is a completely serverless system as well. I’ve been paying $20/mo for my virtual machine that ran matelsky.com since 2014 (up until a week ago, I was still running Ubuntu 14LTS), and I thought it was time for a change.
My requirements were simple:
- Host a static site at matelsky.com (my root domain)
- Support the ability to host subdomains, such as jordan.matelsky.com
- Completely seamless deploy process when I push updates to my private repository on GitHub
I figured this would be pretty straightforward, and certainly not interesting enough to warrant an entire blog post.
And then I entered serverless hell.
If you care not for a story and wish only for a Virgil on your own journey, you may scroll bottomward for a seven-step recipe.
Kickoff
My thought-process was pretty simple: I wanted a virtually free way to host a static site. Well, there are plenty of those. In fact, the easiest would be to just host through GitHub pages, which is already how I host this blog that you’re reading now. But most static-site hosts don’t support subdomains, and GitHub pages is notoriously bad at CNAME subdomain SSL. So instead, I decided to use Amazon Web Services technologies. Worst-case, it would be a good exercise in using AWS tools.
The Plan
My intention was to use AWS s3 to mirror a GitHub repository in a bucket, and then redirect subdomain requests (e.g. FOO.matelsky.com) to subdirectories in that bucket (e.g. s3://bucket-name/FOO/). I wasn’t even going to bother with any other serverless technologies; a static bucket seemed sufficient. And the plan was to use Route53 to reroute requests for any of my hosted toys that needed a non-static backend.
But then a problem emerged
But then a problem emerged: s3 redirects don’t quite work the way you’d expect (a StackOverflow answer from 2017 is no longer valid s3-Redirect XML syntax). Not to worry! I’d just use CloudFront to intercept requests, and then relay them over to s3, prefixed with a path based upon the appropriate subdomain.
In order to use CloudFront to serve a custom domain accessed via Route53, you need a custom SSL certificate. These are free using the AWS certificate manager, but provisioning one takes a few minutes, during which time you can’t provision your CloudFront distribution (the name for the redirect that CloudFront performs to direct your request to the AWS resource it’s wrapping). The CloudFront distribution itself takes about 10 minutes to go from “created” to “deployed,” during which time you can nondeterministically access it via a browser. (It was around this time that I entered DNS purgatory: I had no idea why my page was nondeterminstically alternating between SSL errors, the old VM server — which must have been the result of a DNS cache — and the fully-working serverless version… But it was absolutely random, and this lasted for about two hours until I went to bed.) If you follow in my footsteps on this style of project, this is a good time to go to lunch and assume that things will work themselves out before you get back.
An important note: If you try hitting this in your browser (as I did), you’ll usher the old DNS records into a cache which you are powerless to purge. If you want it to go faster, you (paradoxically) must NOT try hitting the site.
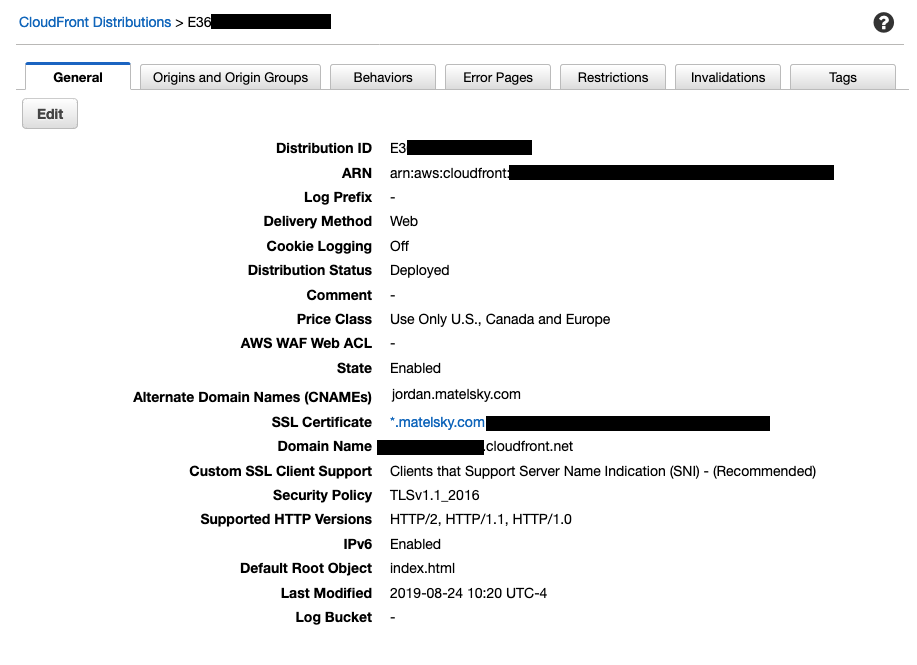
The default root object débâcle
By this point, I had a “root” cloudfront distribution provisioned for matelsky.com, and then I had a different distribution provisioned for each subdomain, which had the same Origin Behavior. The s3 bucket that was behind all of these had full public read permissions turned on, and I even enabled +Static website hosting in the s3 bucket settings for good measure.
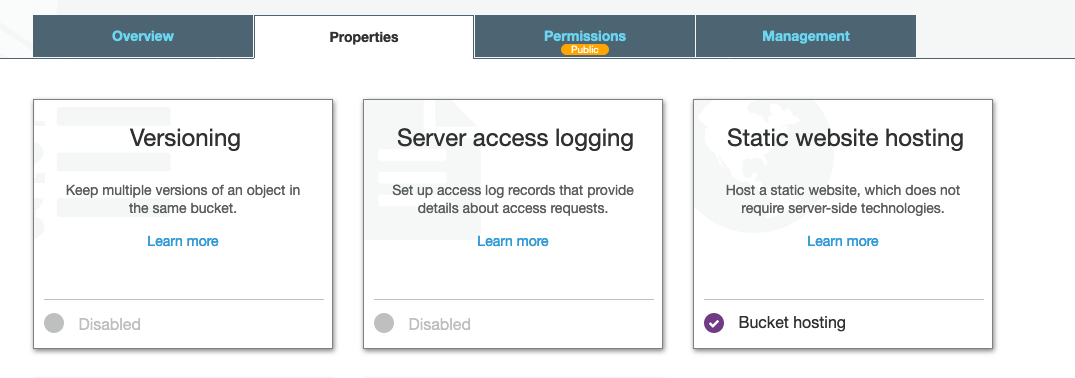
I originally had all of the subdomains as different Origins in the same CF distribution, but evidently, even though you can notate that they should point to different subdirectories in your s3 bucket, in practice this has no effect, and they all point to the s3 root. The AWS documentation kinda hints at this, but it took more research to figure out what was actually going on.
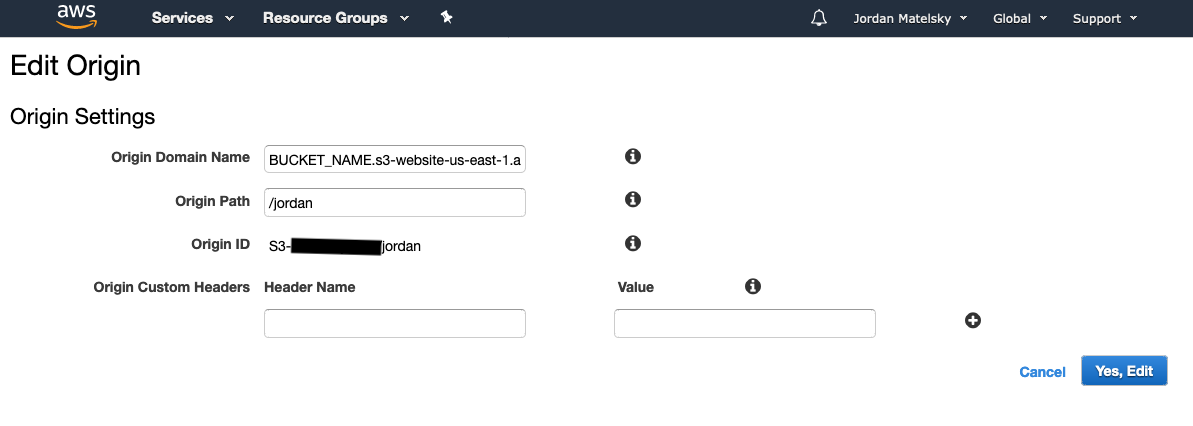
This needs to be in its own CF distribution. Adding multiple Origins with different directory pointers to the same distribution has no effect.
You can specify a root object — as I did in the above CloudFront screenshart — so that navigating to matelsky.com automatically passes your request along to the bucket’s index.html object.
But.
This default root object only works at the top level of your bucket. So matelsky.com/foo/ doesn’t forward to bucket/foo/index.html; it throws a permissions error.
WHY does it throw an Access Denied error in the browser? I have all public read permissions enabled in s3, so it couldn’t be that, right..?
It’s because CloudFront isn’t forwarding your request to s3’s HTTP endpoint: It’s using the AWS API to request an object from s3, and then it’s producing an HTTP response with that blob as the body. Requesting a directory from s3 is an invalid API call, so rather than producing a 404, it produces a permission-denied; the same error it would give to mask that you’re trying to see something you’re not allowed to request. I’m not sure I love this paradigm, but that’s neither here nor there.
So how do you serve a root index.html file from a “directory”-notation URL?
Lambda@Edge
Let me spoil the surprise by telling you that this doesn’t work. I don’t have a more nuanced explanation than that; I just spent two days wrestling with Lambda@Edge and couldn’t get anything productive out of it.
But theoretically you can deploy a serverless AWS function (Lambda) that is triggered by a CloudFront request, which serves as a redirect that the above linked StackOverflow issue would have done were it valid AWS s3 Redirect XML. This is documented in an AWS blog post here, but I will warn you ahead of time that their screenshots are out-of-date, and you can no longer link a Lambda’s permissions in the way they demo there.
This is really cool, but, hey, two caveats:
- If you’re deploying at scale, this could pretty substantially increase the cost of your deploy: You’re now getting charged for Lambda execution time on every page hit, even if it would have otherwise been cached in CloudFront
- It does not work
So how are we going to specify a default root object at non-root URLs?
Steve Papadopoulos encountered and fixed this issue, and discussed it a bit in a blog post. As of writing this, I can no longer access that blog post, which means that had I been slightly lazier and tried to manage this a week later than I did, I’d be absolutely SOL.
The solution is to point your CloudFront distributions at the s3 website URL (bucket.s3.amazon-aws.com) rather than the bucket’s identifier. It is not particularly obvious to me that these two otherwise identical references would behave so substantially differently, and yet here we are.
Unedging Lambda
Alright, so… Tear down those Lambda@Edge functions. We won’t be needing those.
In order to do this, you need to disable them from the CloudFront origins that they modified in the background without telling you. Otherwise, deleting them from the Lambda homepage will result in a error message that does not actually point to the offending Distribution.
Time to deploy!
This was the fun part: I wanted a GitHub Webhook to fire when I pushed updates to my site, and — since now I was just pushing to a bucket, I could just upload the repo as-is to s3.
GitHub Webhooks are great: They just send a HTTP POST to a URL of your choice when an event of your choice takes place.
This is the perfect complement to AWS Lambda triggered by the API Gateway trigger: You can trivially get a Lambda to respond to an HTTP POST. (I’d recommend loading that token into your Lambda’s environment variables rather than hardcoding it inline.)
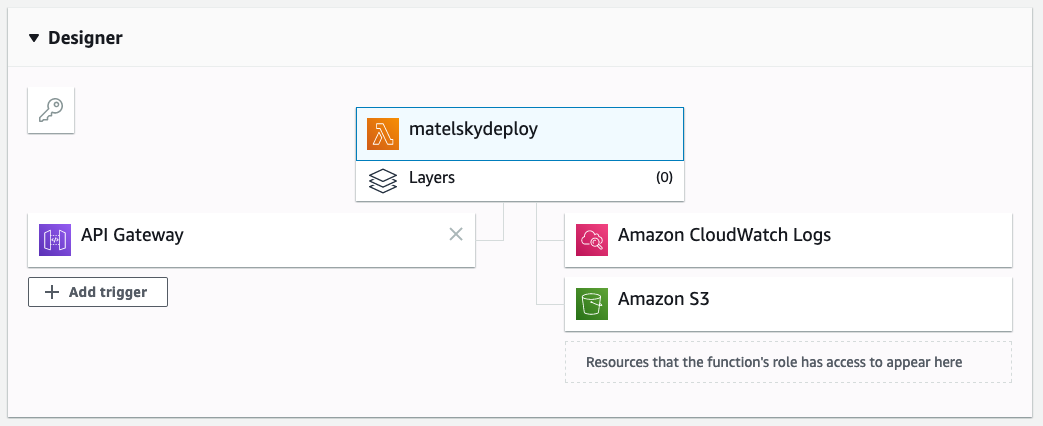
My lambda code (Python) is available below: It downloads a tarball archive of the git repo (you’ll need to set up an API token if you’re trying to pull from a private repo) into the /tmp directory of the Lambda itself (which is the only directory on a Lambda you’re allowed to write to), and then uses boto3, the AWS Python API, to upload that to s3. Easy.
Except that if you upload files with boto3, it doesn’t automatically guess the file’s MIME types. Which means that when you navigate to your homepage, it’ll ask if you want to download a binary octet-stream version of your HTML page. (This is easily fixed with the stdlib mimetypes package in Python.)
import json
import urllib
import tarfile
import time
from uploader import upload_directory
PATH = "/tmp/archive.tar.gz"
UNZIPPATH = "/tmp/archive"
URL = "https://api.github.com/repos/:user/:repo/tarball"
BUCKET_NAME = "YOUR_s3_BUCKET"
import glob
def download_file(url, path):
req = urllib.request.Request(url, headers={ "Authorization": "token YOUR_GITHUB_TOKEN_HERE" })
with urllib.request.urlopen(req) as res:
with open(path, 'wb') as fh:
fh.write(res.read())
def unzip_file(path):
tf = tarfile.open(PATH)
tf.extractall(UNZIPPATH)
def lambda_handler(event, context):
tic = time.time()
download_file(URL, PATH)
unzip_file(PATH)
skipped, uploaded = upload_directory(glob.glob(UNZIPPATH + "/*")[0], BUCKET_NAME, prefix="")
return {
'statusCode': 200,
'duration': time.time() - tic,
'skipped': skipped,
'uploaded': uploaded
}
I separated a few utilities into a standalone file:
import os
from concurrent import futures
import boto3
import mimetypes
website_configuration = {
'ErrorDocument': {'Key': 'index.html'},
'IndexDocument': {'Suffix': 'index.html'},
}
def upload_directory(directory, bucket, prefix=""):
s3 = boto3.client("s3")
def error(e):
raise e
def walk_directory(directory):
for root, _, files in os.walk(directory, onerror=error):
for f in files:
yield os.path.join(root, f)
def upload_file(filename):
mimetype, _ = mimetypes.guess_type(filename)
if mimetype:
ExtraArgs={
"ContentType": mimetype
}
else:
ExtraArgs={}
s3.upload_file(
Filename=filename,
Bucket=bucket,
Key=prefix + os.path.relpath(filename, directory),
ExtraArgs=ExtraArgs
)
skipped = 0
uploaded = 0
for filename in walk_directory(directory):
if os.path.basename(filename).startswith(".") or os.path.relpath(filename, directory).startswith(".") or ".git" in filename:
skipped += 1
print("Skipping {}".format(os.path.relpath(filename, directory)))
else:
uploaded += 1
upload_file(filename)
s3.put_bucket_website(
Bucket=bucket, WebsiteConfiguration=website_configuration
)
return (skipped, uploaded)
boto3 conspicuously lacks a way to upload a directory recursively, which is frustrating. Thank you to the many users in Issue #358, and in particular, @rectalogic, for having already solved this problem. Sure wish boto3 would just inline this…
Adding this call to GitHub is easy: Grab the HTTP URL from the API Gateway trigger in the Lambda, and go to /settings/hooks/new in your GH repository settings to add the call:
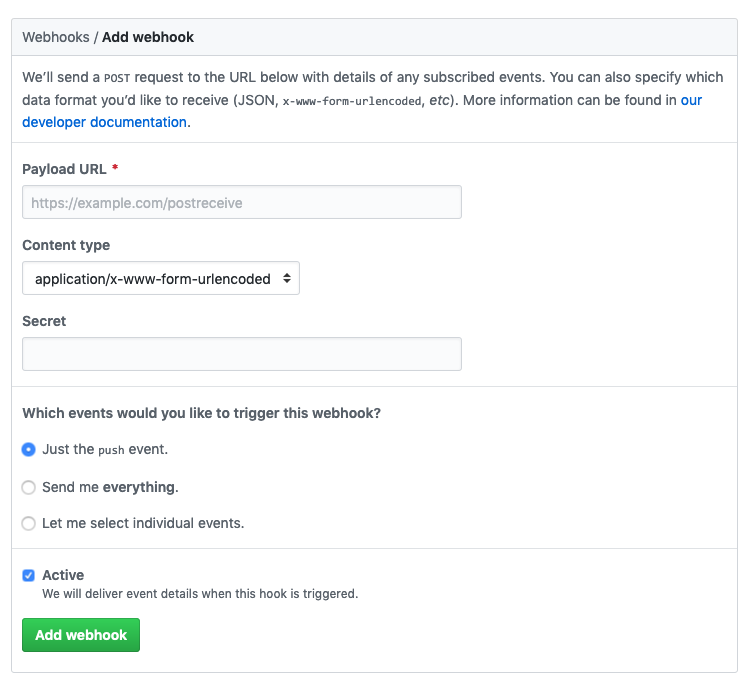
You can trigger on whatever event you like: I just trigger on push. You can ignore the Secret for the purposes of this illustration.
How to serve a website with subdomains using AWS serverless technologies that is auto-updated when you push changes to GitHub
- Set up a Hosted Zone in Route53.
- Configure your SSL certs using ACM.
- If you have already set things up in Route53, you can have AWS validate this for you when you create your certificate.
- There’s a link to ACM from the next step, but if you wait that long to start this process, you’ll have to leave your filled-out CloudFront distribution form and throw away those values because you can’t get the SSL cert to show up in the dropdown list if the page was loaded prior to cert creation.
- While you’re waiting for your SSL cert to validate, create an S3 bucket for your website, with subdomains listed as subdirectories.
- Create a CloudFront distribution for each subdomain, and another for your root domain. Point to your s3 bucket BY WEBSITE URL, not by s3 bucket name. Under “Origin Path”, list the subdirectory you want to point to. Under CNAMES or
Alternate Names, put the full subdomain+domain+TLD. (For example, origin-path is/jordan, and CNAME isjordan.matelsky.com). - Create a rule in Route53 that points that subdomain to the appropriate CloudFront distribution. I haven’t been able to figure out if there’s a difference between “A” and “CNAME” once you check the “Alias” box in Route53, but mine are both A records with an Alias enabled that points to CF, if you want to follow along.
- Wait. A lot of stuff has to propagate right now, including your CF distributions (they’ll tell you they’re ready to go from the CF homepage once they’re ready) and your DNS records (they won’t give you any warning when they’re done propagating). While you’re waiting, set up your deploy Lambda with the code from above.
- Condescend to me in the comments section of Hacker News.